
Extracting form data from PDFs with AWS Textract

In these page, we will write a little bit of Python to extract information from PDF documents; and in this particular instance an invoice.
This data is needed for further processing; and getting information out of these invoices into a computer-readable way is going to be the first step of many of similar data projects.
We will use AWS Textract to perform the operation.
This is a companion article to the code available on Github: https://github.com/tonyp7/aws-textract-redmart
Objectives
Given a folder containing a list of pdf invoices, the objectives are to extract from the documents the following information:
- Date information: order/invoice date
- Invoice table with the different elements: item, quantity, unit price
Data should be exported into a CSV dataframe for the convenience of a another process doing data crunching on the dataset.
Input Data: Redmart Invoice
The invoice data comes from Redmart, a once independent Singapore online supermarket and now subsidiary of Lazada / Alibaba.
I have masked personal information below, but the rest of the invoice data is real. On the available source code on Github, you can find a similar invoice sample with anonymized data.
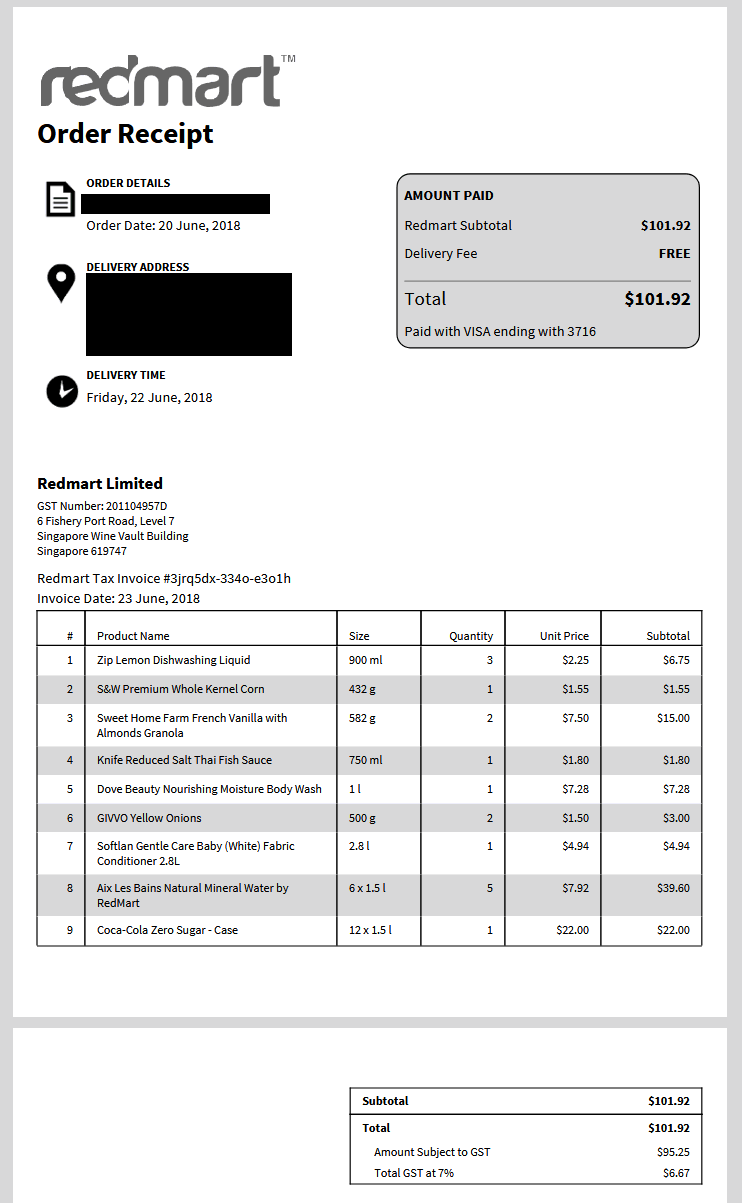
These invoices can span multiple pages and the format has evolved slightly over the years.
For once, the "Size" element of the packaging is now omitted in the more recent invoices. This will make detecting shrinkflation more difficult, as ideally you compare the cost per quantity of product. A can of coca-cola used to be 330ml in Singapore, and it is now 320ml. A brewed-in-Japan Asahi beer is 350ml and cost a lot more than a brewed-in-China 330ml Asahi beer. And so on so forth.
Accounting for these or not is a debate for another post.
Amazon Textract
According to AWS, "Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, layout elements, and data from scanned documents."
AWS Textract is a service that I have encountered a few times on a professional level for different purposes such as extracting information from submission forms and extracting information from a business card.
I was mind blown by its efficacy.
Textract has a demo you can use to see for yourself if the service is suitable on your documents that can be accessed here: https://us-east-1.console.aws.amazon.com/textract/home?region=us-east-1#/demo
On this demo, you can upload a PDF. Textract will ask you what kind of output you'd like to have:
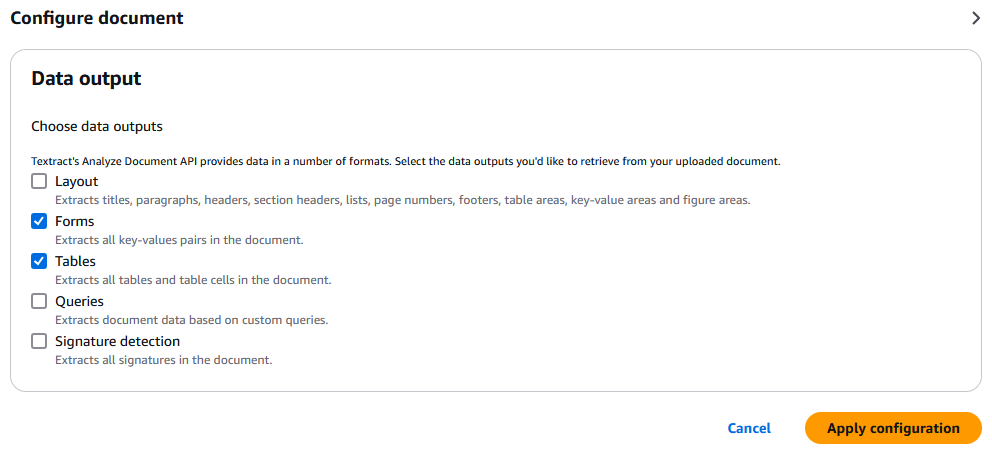
In our cases, we're interested in the forms (key-values pairs such as the dates) and the tables.
Once done, the data appears almost immediately:
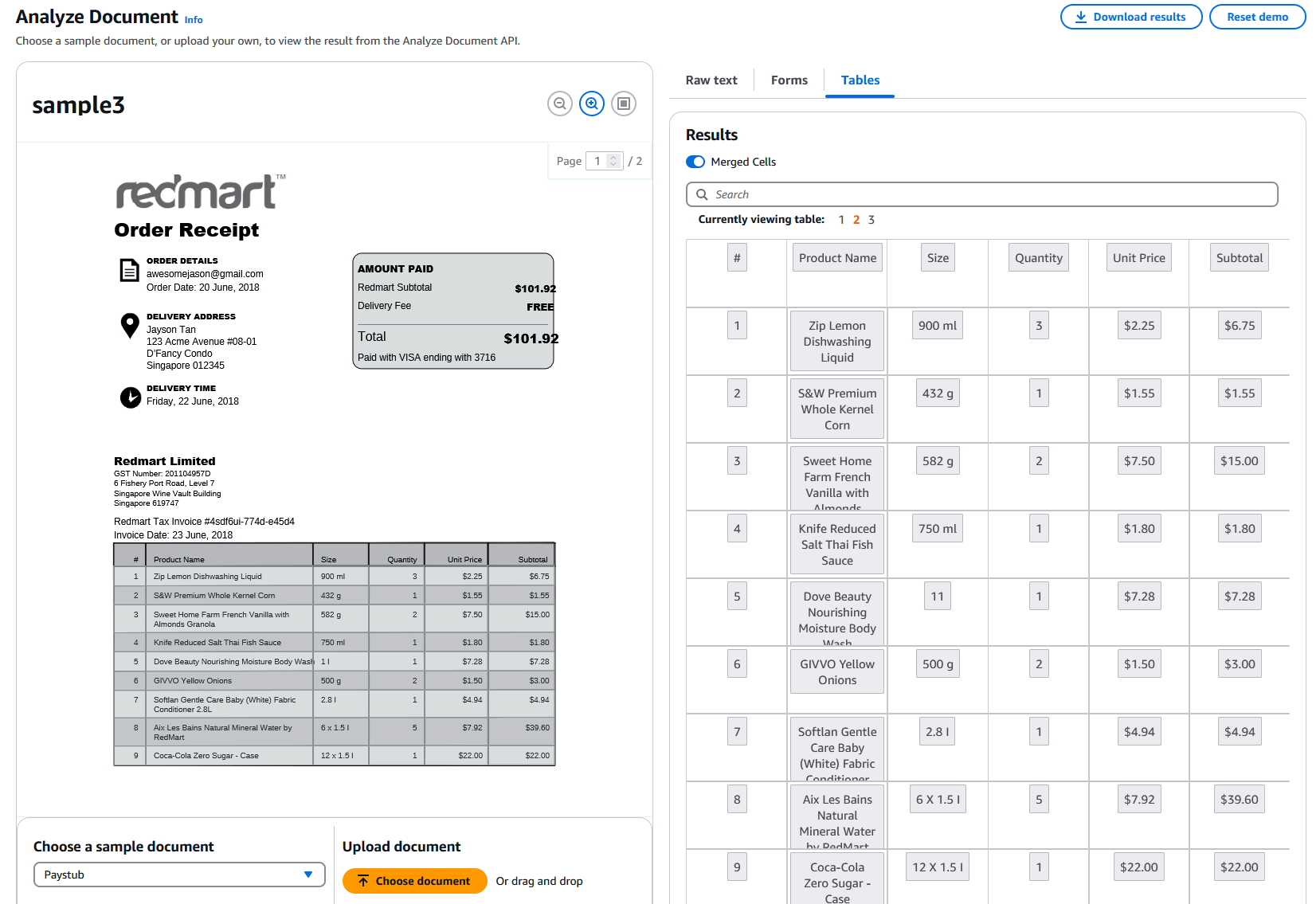
The service is legitimately impressive. The table is extracted almost flawlessly which is why we want. The service is however not without fault. For instance, it failed to extract the order date:
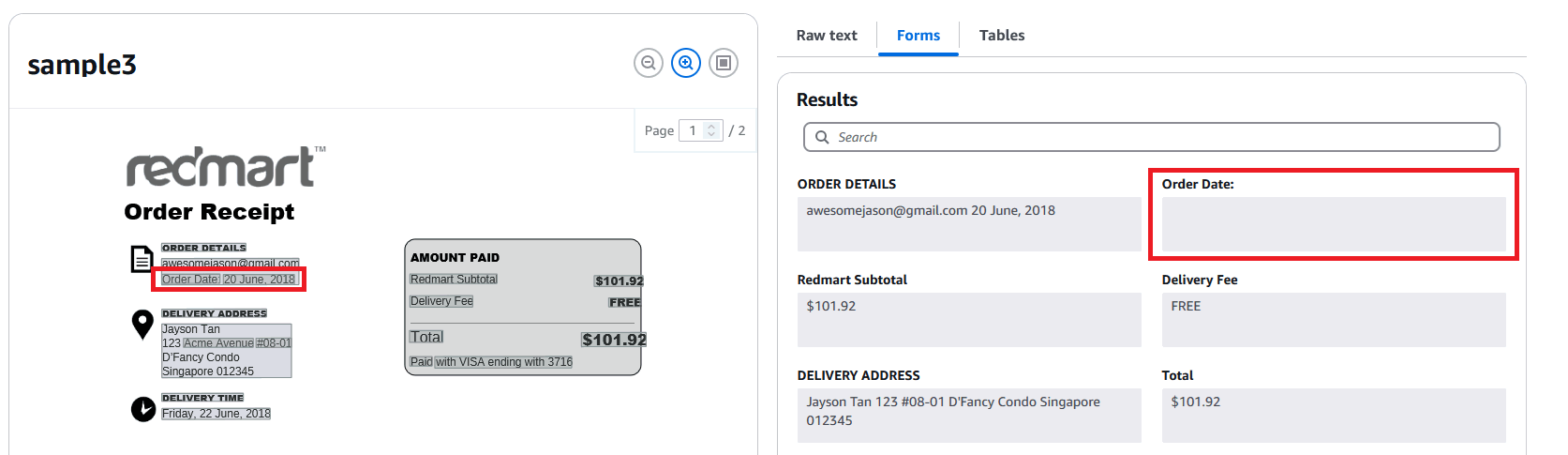
This means that processing the data will require fallback options (e.g. using the invoice date or delivery date for instance)
Using Textract in Practice: Textractor
You'd think you could just call an API with a document and Textract would spit out the results similarly to what the demo shows but that's not the case.
The fact is: the textract API is not very user friendly.
For instance, it can't process synchronously a multiple page PDF such as the sample invoice.
For this use case if you follow the official documentation you'd have to:
- Upload the document to a S3 bucket
- Launch an asynchronous request for processing with a SNS Topic
- Receive a SNS message when the data is ready
- Process the data
And even if you're following all of this, step 4 is not to be scoffed at. The JSON returned by Textract is not something you can easily read without heavy processing.
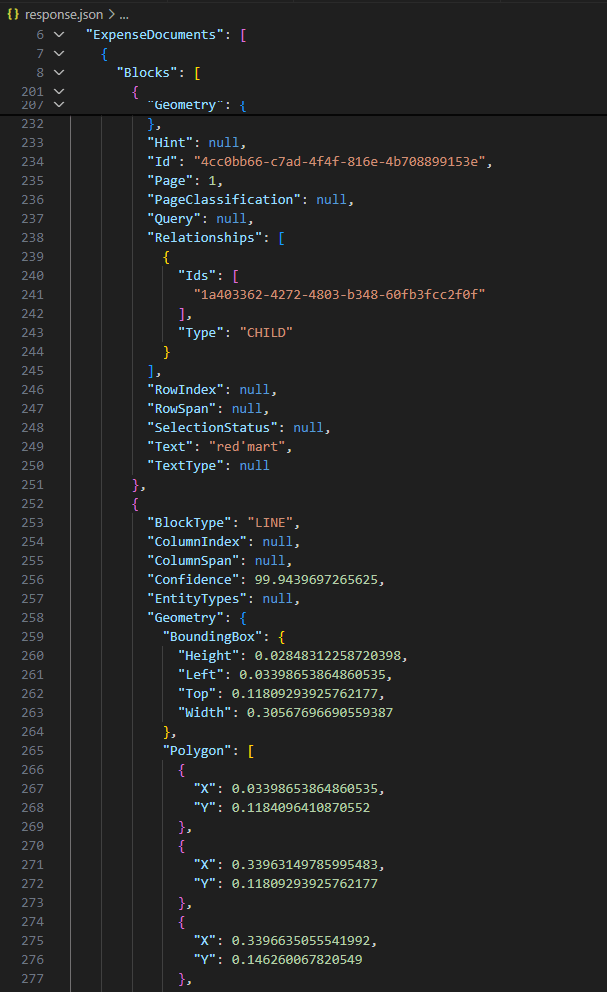
All of these can be done - and AWS provides good examples and sample code on how this can be done - but they all introduce code complexity that quite frankly no user of the Textract service should have to deal with.
Fortunately for us; AWS also provides a Python wrapper called "textractor" which obfuscates much of the complexity of the public APIs for Textract.
Using the Textractor library
Initializing a textractor client is one line of code:
from textractor import Textractor
extractor = Textractor(profile_name="default")
This of course assumes that you have installed the library and that your AWS credentials are already setup. If you enable logging at INFO level you should see the following message when initializing the client.
INFO:botocore.credentials:Found credentials in shared credentials file: ~/.aws/credentials
The second thing needed by the library is a S3 bucket. This is due to a weird limitation of the Textract API where multiple page documents must be uploaded to S3 and processed asynchronously and there is no option to just push the binary directly in the API call, regardless of file size.
The bucket can be anything, but it's just easier to create a bucket for this. In the code provided on github, you will see the following in config.toml:
[aws]
s3_upload_path="s3://textract-7e607b39-c7ba-4547-8794-db30c3ee4d22/"
Now, we can simply call the textractor library in a similar fashion to the AWS Textract demo, with the following call:
document = extractor.start_document_analysis(
'path/to/myfile.pdf',
s3_upload_path='s3://a-valid-bucket/',
features=[TextractFeatures.TABLES, TextractFeatures.FORMS]
)
"start_document_analysis" will start at asynchronous processing; which does not return a Document, but instead a LazyDocument.
Internally, the library handles all the complexity of polling if the AWS Textract analysis is ready; but also it parses and populates the document object with document.table and document.key_values – which matches the TABLES and FORMS feature extraction.
In practice, you can try to access document.tables immediately after the call, but the code will hang a couple of seconds until the tables are actually readily available.
Manipulating Key-Values: extracting the date information
In this particular instance, we are interested in one key only: the date.
The proposed way to do this with textractor would be:
document.get("date")
This returns an array, which should contain date objects. In my experience I found this API unreliable. Date would just return the first object, in this case "Order Date", which textract failed to export.
I found it much more reliable to read through the list of key-values directly, look for a key containing "date"; and attempting to convert the value to a datetime object.
The code became:
def locate_invoice_date(document:Document | LazyDocument) -> datetime | None:
for kv in document.key_values:
if 'date' in kv.key.text.lower():
t = kv.value.text.strip()
d = parse_redmart_date(t)
if d is not None:
return d
#no date was found
return None
Manipulating Tables: export to CSV
Each table is the list document.tables is of the type textractor.entities.table. This is not something that most people are accustomed to and thinking about dataframes.
For this matter, the library provides a method to transform the table into multiple formats, including Pandas dataframe, CSV and Excel.
An important parameter of the to_pandas() is "use_columns" which is set to False by default. This has the effect of not considering the first row as the header column. Instead the pandas dataframe will contain numbered columns.
For a data extraction, I would consider leaving this default behavior. This allows us to trim all the newlines created by Textract.
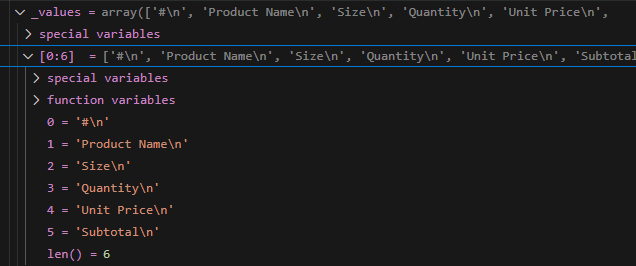
This way we can clean it all up by simply doing:
df = t.to_pandas(use_columns=False)
df = df.replace(r'\n',' ', regex=True)
df = df.replace(r'\r',' ', regex=True)
Then it's easy to save this as a proper CSV while ignoring the automatically generated index and headers by Pandas:
df.to_csv(output_file, index=False, header=False)
This generates a valid CSV that will be easy to read for the next data processing step.
Final Result
In a few lines of code and some light processing, it was very easy to extract invoice data from a PDF and save them as a readable CSV.
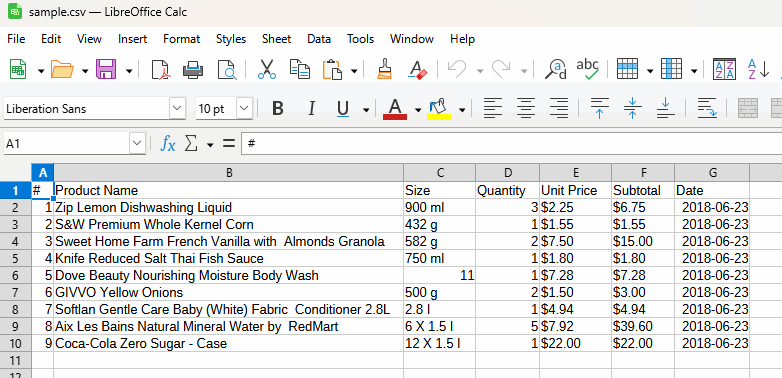
AWS did the heavy lifting here but can we do things differently?
Pricing consideration
AWS Textract is very costly.
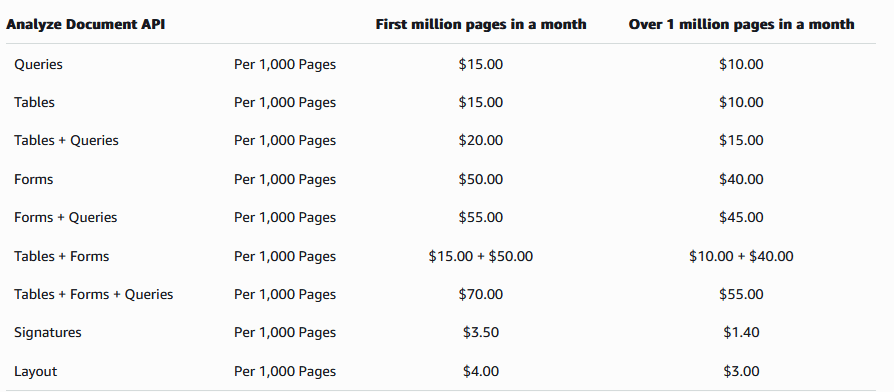
Tables+Forms, which the operation we ran here, costs US$65 per 1000 pages, or $0.065 per page. Since most our invoices are 2 pages long, each call costs 13c not including the cost of S3.
~15c for ~5 seconds of compute time is insanely expensive.
To put things in perspective, this would be $2,592 per month or $77,760 per month.
For this price at Amazon you can get a u-6tb1.112xlarge (448 CPUs, 64 TB of RAM) on demand EC2 running at 100% utilization and still save $27k a month.
A note on some alternatives
PDF data mining is not exactly a new need; so over the years and before the AI/ML craze there have been quite a number of attempts at solving this problem. Below I will name a few.
There's a legitimate point to be made here: why would I send my data to cloud services if I can process it locally?
Some local libraries include:
PDF Miner
PDF Miner is very good at extracting text and layouts from PDF but cannot export tables directly. This means in order to use it for our purpose we'd have to roll our own layout-detector-parser for our tables.
Tabula
Tabula is a Java library that was developed specifically for the purpose of extracting tables from PDF. It has a python-wrapper, but you still need to have a JVM to run it of course.
Camelot
Camelot is a python library that is also made to extract tables. In a quick test, it failed to detect any tables in the sample PDF where AWS Textract found 3.
All these solutions could work; but they would require a significant investment of engineering time for a result that may not match what AWS Textract can do.
Here we must keep the objective in mind which is extracting the data. Throwing money at a cloud service in this case may seem to be a better usage of time than rolling out a complex local solution. Some engineers might disagree and this is okay.
Links
- Code used in this page: https://github.com/tonyp7/aws-textract-redmart
- AWS Textractor github library page: https://github.com/aws-samples/amazon-textract-textractor